
Wind Noise Reduction with a Diffusion-based Stochastic Regeneration Model
15 Sep 2023
- Keywords :
-
- Diffusion Models
- Wind Noise
- Speech Enhancement
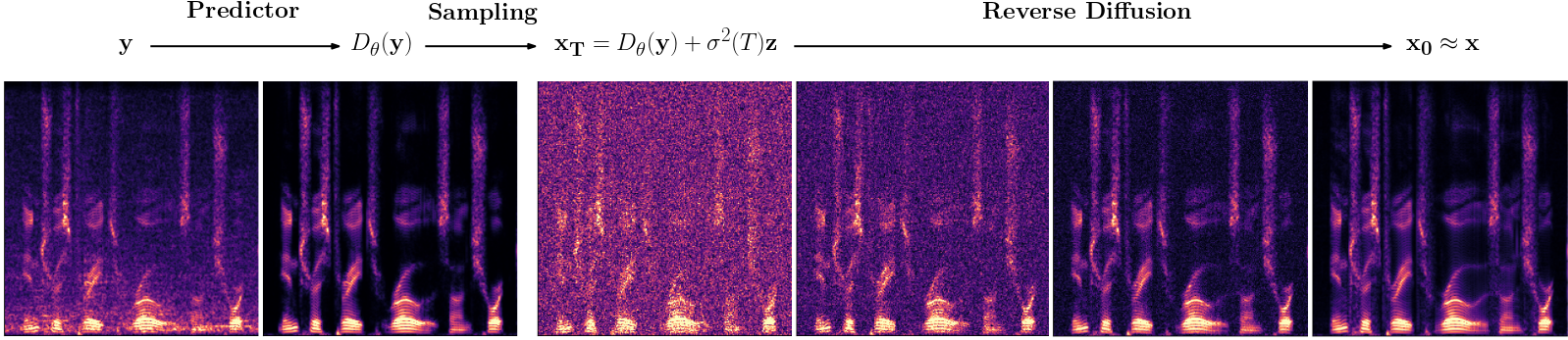
In this paper we present a method for single-channel wind noise reduction using our previously proposed diffusion-based stochastic regeneration model combining predictive and generative modelling. We introduce a non-additive speech in noise model to account for the non-linear deformation of the membrane caused by the wind flow and possible clipping.
We show that our stochastic regeneration model outperforms other neural-network-based wind noise reduction methods as well as purely predictive and generative models, on a dataset using simulated and real-recorded wind noise. We further show that the proposed method generalizes well by testing on an unseen dataset with real-recorded wind noise. Audio samples, data generation scripts and code for the proposed methods can be found online.