DiLaDiff: Distilled Latent-Augmented Diffusion for Language Modeling
arXiv preprint · NeurIPS 2026 submission
Jean-Marie Lemercier, Tomas Geffner, Morteza Mardani, Karsten Kreis, Arash Vahdat, Ante Jukić
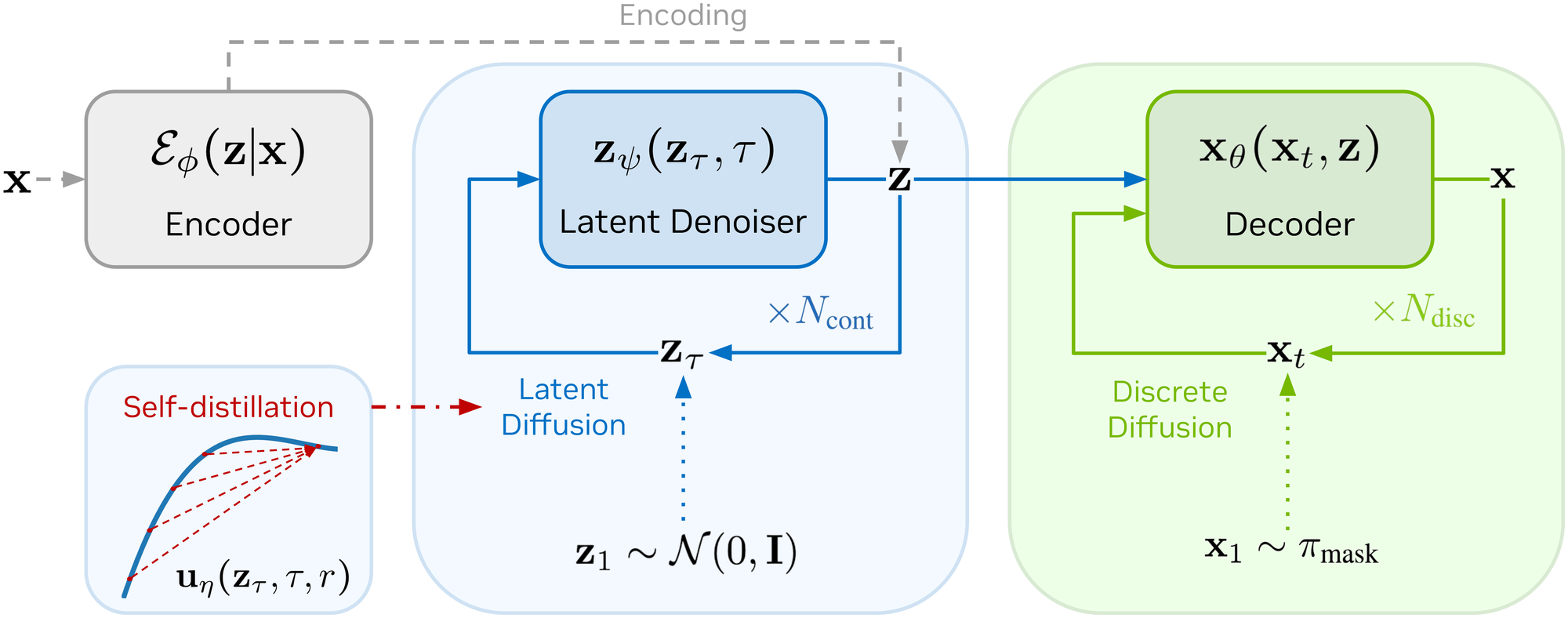
Diffusion language models intrinsically fail to capture correlations between decoded tokens, which leads to a harsh trade-off between sampling quality and throughput. To solve this issue, we propose DiLaDiff, a variant of masked diffusion language models with three components: (1) a continuous latent space with semantic capabilities, learned by an auto-encoder fine-tuned from an existing masked diffusion language model; (2) a latent diffusion model learning the prior over the encoder distribution; (3) a consistency model distilling the learned prior into a few-step latent generative model. Even without distillation, our latent-guided diffusion model outperforms the masked diffusion baseline while significantly accelerating inference. Consistency distillation further lowers the computational overhead of continuous diffusion, such that the latent is generated in negligible time compared to discrete decoding.
Model-based Techniques and Diffusion Models for Speech Dereverberation
PhD Dissertation · Universität Hamburg · February 2025
Jean-Marie Lemercier — supervised by Prof. Dr.-Ing. Timo Gerkmann
My PhD thesis on the joint use of model-based techniques and diffusion models for speech dereverberation, conducted in the Signal Processing group at Universität Hamburg in collaboration with Advanced Bionics. The first part covers hybrid signal-processing / DNN methods for real-time dereverberation on hearing devices (online WPE, Kalman filtering, multi-frame post-filtering). The second part introduces score-based generative models for general speech restoration, both in the informed (known room impulse response) and blind / unsupervised regimes, culminating in StoRM (stochastic regeneration) and BUDDy (blind unsupervised dereverberation via posterior sampling).
Unsupervised Blind Joint Dereverberation and Room Acoustics Estimation with Diffusion Models
IEEE/ACM TASL · submitted 2024
Jean-Marie Lemercier, Eloi Moliner, Simon Welker, Vesa Välimäki, Timo Gerkmann
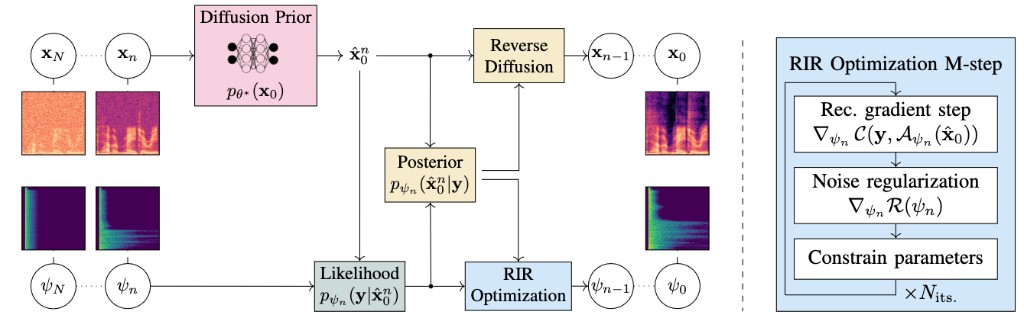
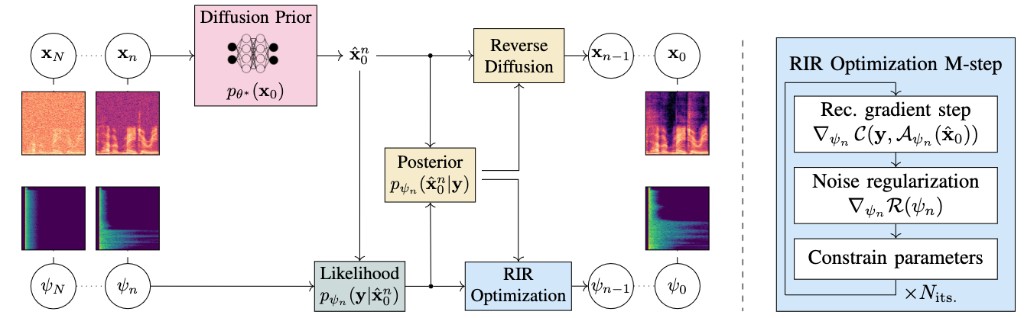
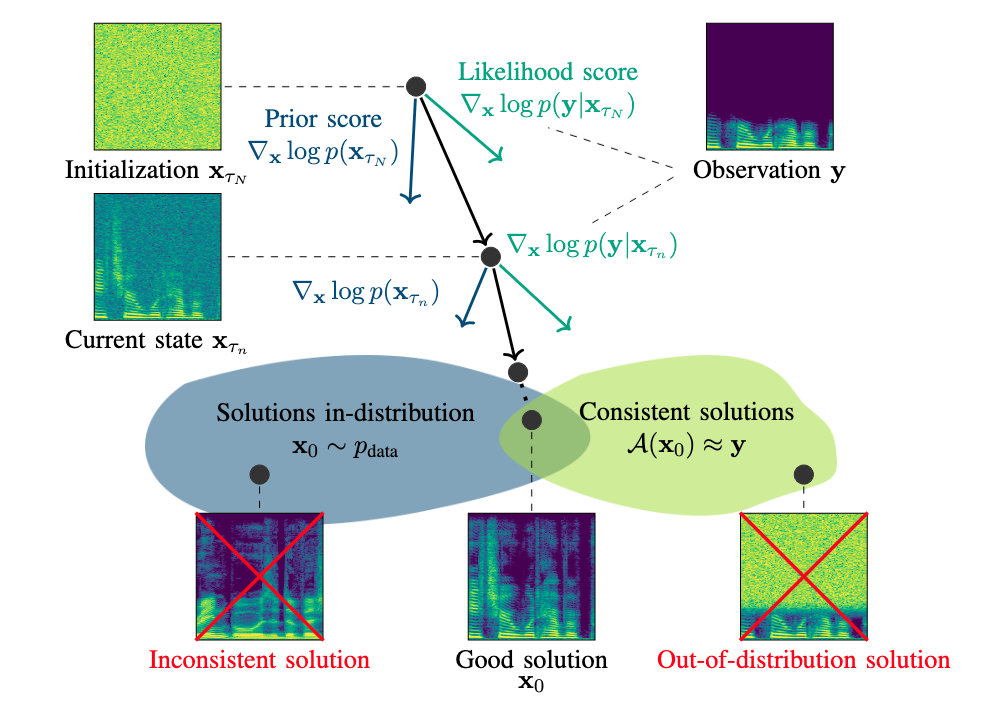
This paper presents an unsupervised method for single-channel blind dereverberation and room impulse response (RIR) estimation, called BUDDy. The algorithm is rooted in Bayesian posterior sampling: it combines a likelihood model enforcing fidelity to the reverberant measurement, and an anechoic speech prior implemented by an unconditional diffusion model. We design a parametric filter representing the RIR, with exponential decay for each frequency subband. Room acoustics estimation and speech dereverberation are jointly carried out, as the filter parameters are iteratively estimated and the speech utterance refined along the reverse diffusion trajectory. In a blind scenario where the RIR is unknown, BUDDy successfully performs speech dereverberation in various acoustic scenarios, significantly outperforming other blind unsupervised baselines. Unlike supervised methods, which often struggle to generalize, BUDDy seamlessly adapts to different acoustic conditions. This paper extends our previous work by offering new experimental results and insights into the algorithm's versatility, including high-resolution singing voice dereverberation, robustness to RIR estimation errors, and a comparison to state-of-the-art supervised DNN-based estimators on mismatched conditions.
BUDDy — Single-Channel Blind Unsupervised Dereverberation with Diffusion Models
IWAENC 2024
Eloi Moliner, Jean-Marie Lemercier, Simon Welker, Timo Gerkmann, Vesa Välimäki
We present an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models. We parameterize the reverberation operator using a filter with exponential decay for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory. A measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation. Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we can successfully perform dereverberation in various acoustic scenarios. Our method significantly outperforms previous blind unsupervised baselines, and we demonstrate its increased robustness to unseen acoustic conditions in comparison to blind supervised methods.
An Independence-promoting Loss for Music Generation with Language Models
ICML 2024
Jean-Marie Lemercier, Simon Rouard, Jade Copet, Yossi Adi, Alexandre Défossez
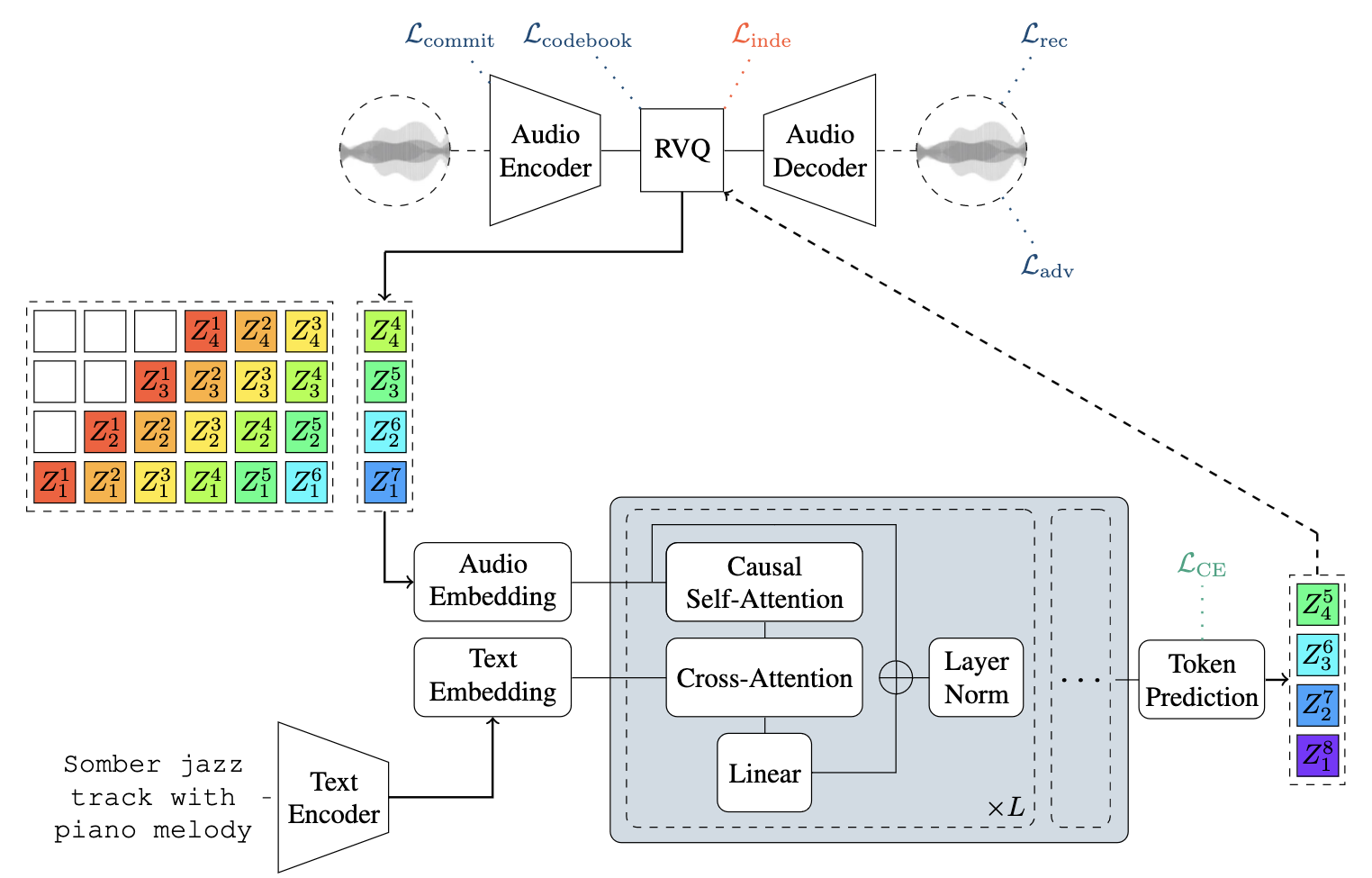
Music generation schemes using language modeling rely on a vocabulary of audio tokens, generally provided as codes in a discrete latent space learnt by an auto-encoder. Multi-stage quantizers are often employed to produce these tokens, therefore the decoding strategy used for token prediction must be adapted to account for multiple codebooks: either it should model the joint distribution over all codebooks, or fit the product of the codebook marginal distributions. Modelling the joint distribution requires a costly increase in the number of auto-regressive steps, while fitting the product of the marginals yields an inexact model unless the codebooks are mutually independent. In this work, we introduce an independence-promoting loss to regularize the auto-encoder used as the tokenizer in language models for music generation. The proposed loss is a proxy for mutual information based on the maximum mean discrepancy principle, applied in reproducible kernel Hilbert spaces. Our criterion is simple to implement and train, and it is generalizable to other multi-stream codecs. We show that it reduces the statistical dependence between codebooks during auto-encoding, leading to higher generated music quality when modelling the product of the marginal distributions, while generating audio much faster than the joint distribution model.
Diffusion Models for Audio Restoration
IEEE Signal Processing Magazine · 2024
Jean-Marie Lemercier, Julius Richter, Simon Welker, Eloi Moliner, Vesa Välimäki, Timo Gerkmann
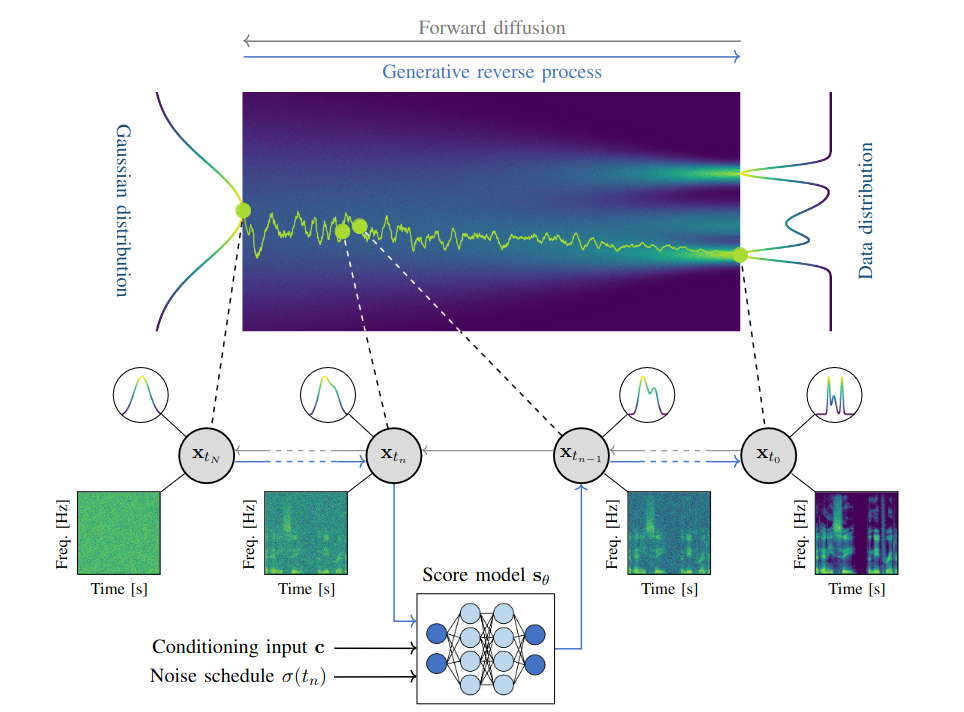
With the development of audio playback devices and fast data transmission, the demand for high sound quality is rising for both entertainment and communications. In this quest for better sound quality, challenges emerge from distortions and interferences originating at the recording side or caused by an imperfect transmission pipeline. Audio restoration methods aim to recover clean sound signals from the corrupted input data. We present here audio restoration algorithms based on diffusion models, with a focus on speech enhancement and music restoration tasks. Traditional approaches, often grounded in handcrafted rules and statistical heuristics, have shaped our understanding of audio signals; in the past decades, a notable shift has occurred towards data-driven methods that exploit the modeling capabilities of deep neural networks. Diffusion models in particular have emerged as powerful generative techniques for learning complex data distributions. We aim to show that they can combine the best of both worlds, offering audio restoration algorithms with a good degree of interpretability and a remarkable performance in terms of sound quality.
Diffusion Posterior Sampling for Informed Single-Channel Dereverberation
WASPAA 2023
Jean-Marie Lemercier, Simon Welker, Timo Gerkmann
We present an informed single-channel dereverberation method based on conditional generation with diffusion models. With knowledge of the room impulse response, the anechoic utterance is generated via reverse diffusion using a measurement consistency criterion coupled with a neural network that represents the clean speech prior. The proposed approach is largely more robust to measurement noise compared to a state-of-the-art informed single-channel dereverberation method, especially for non-stationary noise. Furthermore, we compare to other blind dereverberation methods using diffusion models and show superiority of the proposed approach for large reverberation times. We motivate the presented algorithm by introducing an extension for blind dereverberation allowing joint estimation of the room impulse response and anechoic speech.
Wind Noise Reduction with a Diffusion-based Stochastic Regeneration Model
VDE 15th ITG Conference on Speech Communication · 2023
Jean-Marie Lemercier, Joachim Thiemann, Raphael Koning, Timo Gerkmann
In this paper we present a method for single-channel wind noise reduction using our previously proposed diffusion-based stochastic regeneration model combining predictive and generative modelling. We introduce a non-additive speech-in-noise model to account for the non-linear deformation of the membrane caused by the wind flow and possible clipping. We show that our stochastic regeneration model outperforms other neural-network-based wind noise reduction methods as well as purely predictive and generative models, on a dataset using simulated and real-recorded wind noise. We further show that the proposed method generalizes well by testing on an unseen dataset with real-recorded wind noise.
StoRM — A Diffusion-based Stochastic Regeneration Model for Speech Enhancement and Dereverberation
IEEE/ACM TASL · 2023
Jean-Marie Lemercier, Julius Richter, Simon Welker, Timo Gerkmann
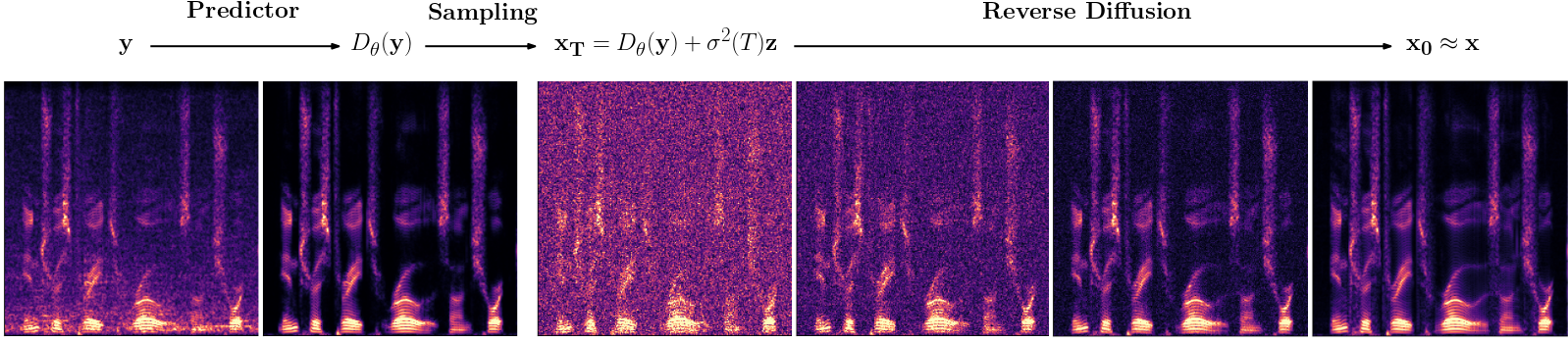
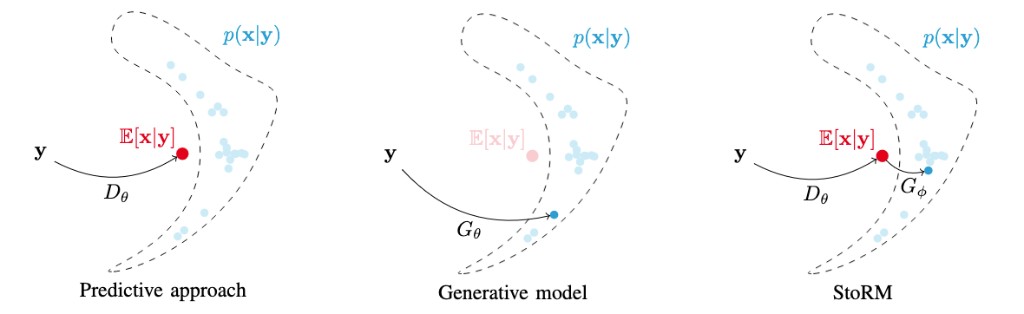
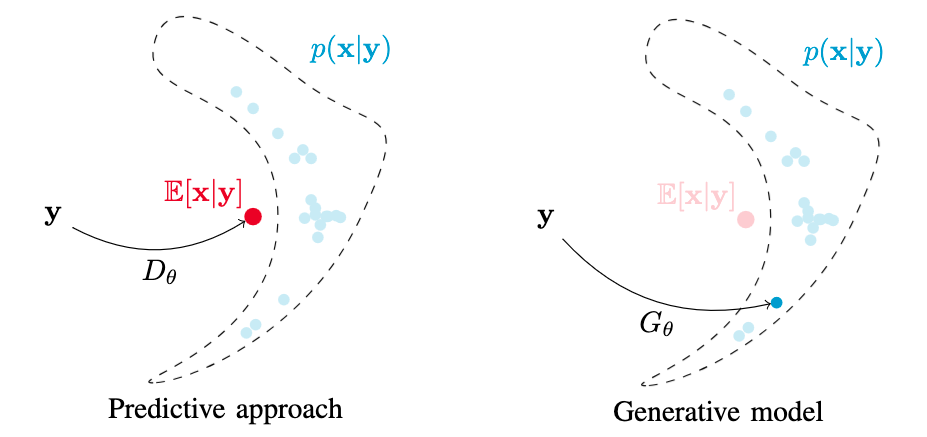
Diffusion models have shown a great ability at bridging the performance gap between predictive and generative approaches for speech enhancement. We have shown that they may even outperform their predictive counterparts for non-additive corruption types or when they are evaluated on mismatched conditions. However, diffusion models suffer from a high computational burden, mainly as they require running a neural network for each reverse diffusion step. As generative approaches they may also produce vocalizing and breathing artifacts in adverse conditions. In comparison, in such difficult scenarios, predictive models typically do not produce such artifacts but tend to distort the target speech instead. In this work, we present a stochastic regeneration approach where an estimate given by a predictive model is provided as a guide for further diffusion. The proposed approach uses the predictive model to remove the vocalizing and breathing artifacts while producing very high quality samples thanks to the diffusion model, even in adverse conditions. We further show that this enables lighter sampling schemes with fewer diffusion steps without sacrificing quality, lifting the computational burden by an order of magnitude.
Extending DNN-based Multiplicative Masking to Deep Subband Filtering for Improved Dereverberation
Interspeech 2023
Jean-Marie Lemercier, Julian Tobergte, Timo Gerkmann
In this paper, we present a scheme for extending deep neural network-based multiplicative maskers to deep subband filters for speech restoration in the time-frequency domain. The resulting method can be generically applied to any deep neural network providing masks in the time-frequency domain, while requiring only few more trainable parameters and a computational overhead that is negligible for state-of-the-art neural networks. We demonstrate that the resulting deep subband filtering scheme outperforms multiplicative masking for dereverberation while leaving the denoising performance virtually the same. We argue that this is because deep subband filtering in the time-frequency domain fits the subband approximation often assumed in the dereverberation literature, whereas multiplicative masking corresponds to the narrowband approximation generally employed in denoising.
A Neural Network-supported Two-stage Algorithm for Lightweight Dereverberation on Hearing Devices
EURASIP Journal on Audio, Speech, and Music Processing · 2023
Jean-Marie Lemercier, Joachim Thiemann, Raphael Koning, Timo Gerkmann
A two-stage lightweight online dereverberation algorithm for hearing devices is presented. The approach combines a multi-channel multi-frame linear filter with a single-channel single-frame post-filter. Both components rely on power spectral density (PSD) estimates provided by deep neural networks. By deriving new metrics analyzing the dereverberation performance in various time ranges, we confirm that directly optimizing for a criterion at the output of the multi-channel linear filtering stage results in a more efficient dereverberation than placing the criterion at the output of the DNN to optimize the PSD estimation. Training this stage end-to-end further removes the reverberation in the range accessible to the filter, increasing the early-to-moderate reverberation ratio. The proposed two-stage system is shown to be both very effective in terms of dereverberation performance and computational demands, and can be adapted to the needs of different types of hearing-device users by controlling the amount of reduction of early reflections.
Analysing Diffusion-based Generative Approaches versus Discriminative Approaches for Speech Restoration
ICASSP 2023
Jean-Marie Lemercier, Julius Richter, Simon Welker, Timo Gerkmann
Diffusion-based generative models have had a high impact on the computer vision and speech processing communities. Beyond data generation tasks, they have also been employed for data restoration tasks like speech enhancement and dereverberation. While discriminative models have traditionally been argued to be more powerful e.g. for speech enhancement, generative diffusion approaches have recently been shown to narrow this performance gap considerably. In this paper, we systematically compare the performance of generative diffusion models and discriminative approaches on different speech restoration tasks. We extend our prior contributions on diffusion-based speech enhancement in the complex time-frequency domain to bandwidth extension, then compare to a discriminatively trained neural network with the same architecture on three restoration tasks: speech denoising, dereverberation and bandwidth extension. We observe that the generative approach performs globally better than its discriminative counterpart on all tasks, with the strongest benefit for non-additive distortion models such as dereverberation and bandwidth extension.
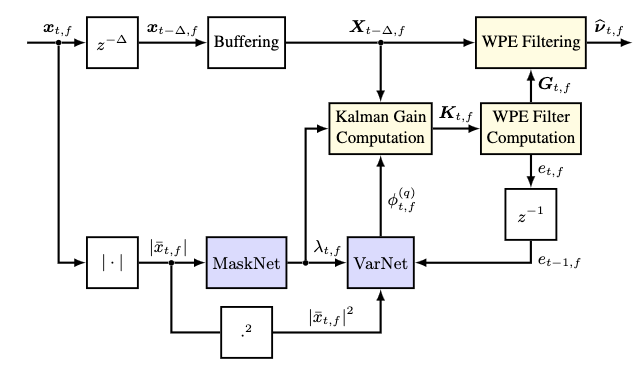
Neural Network-augmented Kalman Filtering for Robust Online Speech Dereverberation in Noisy Reverberant Environments
Interspeech 2022
Jean-Marie Lemercier, Joachim Thiemann, Raphael Konig, Timo Gerkmann
A neural network-augmented algorithm for noise-robust online dereverberation with a Kalman filtering variant of the weighted prediction error (WPE) method is proposed. The filter stochastic variations are predicted by a deep neural network trained end-to-end using the filter residual error and signal characteristics. The presented framework allows for robust dereverberation on a single-channel noisy reverberant dataset similar to WHAMR!. The proposed approach avoids the distortions introduced by the Kalman filtering WPE in noisy conditions by correcting the filter variations estimation in a data-driven way, increasing the robustness of the method to noisy scenarios. It yields strong dereverberation and denoising performance compared to a DNN-supported recursive least squares variant of WPE, especially for highly noisy inputs.
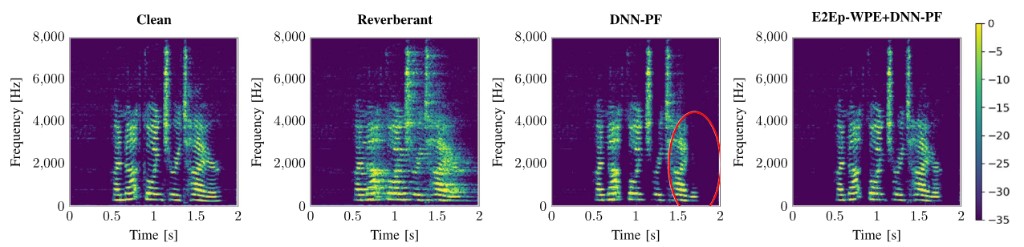
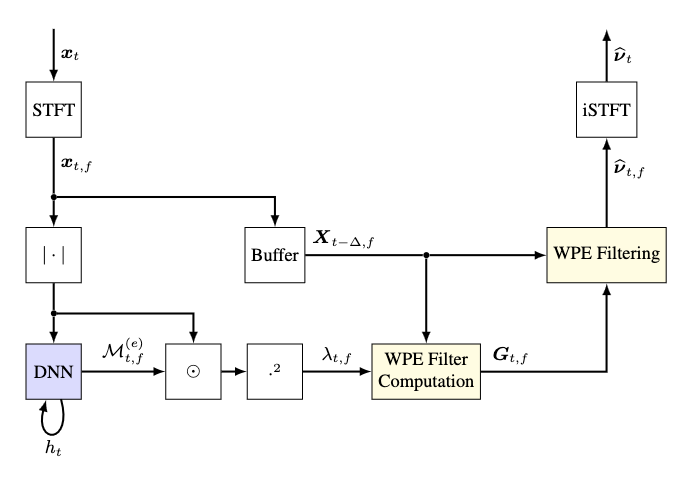
Customizable End-to-end Optimization of Online Neural Network-supported Dereverberation for Hearing Devices
ICASSP 2022
Jean-Marie Lemercier, Joachim Thiemann, Raphael Konig, Timo Gerkmann
This work focuses on online dereverberation for hearing devices using the weighted prediction error (WPE) algorithm. WPE filtering requires an estimate of the target speech power spectral density (PSD). Recently, deep neural networks have been used for this task; however, these approaches optimize the PSD estimate which only indirectly affects the WPE output, thus potentially resulting in limited dereverberation. In this paper, we propose an end-to-end approach specialized for online processing, that directly optimizes the dereverberated output signal. We further propose to adapt it to the needs of different types of hearing-device users by modifying the optimization target as well as the WPE algorithm characteristics used in training. The proposed end-to-end approach outperforms the traditional and conventional DNN-supported WPEs on a noise-free version of the WHAMR! dataset.